A Model that Retrieves Documents When in Doubt
Summary of Active retrieval augmented generation paper

Search for a command to run...
Summary of Active retrieval augmented generation paper
No comments yet. Be the first to comment.
Classifying digits using Apple M1 GPU

Narrowing performance gap with cross-encoder using weakly labeled data
Large Language Model for Commercial Purpose

Training data-efficient image transforms & distillation through attention

TL;DR: Active retrieval augmented generation system checks the quality of each sentence before outputting them. If the quality is questionable, it will retrieve additional documents and re-generate that sentence.
The retrieval method supports LLM generation by minimizing hallucination. It supplies facts for the LLM to reference during generation, typically by retrieving a set of relevant documents at the start of the process.
However, relying on a single retrieval may lead to incomplete information. LLMs have a tendency to creatively structure their responses. For instance, consider discussing Joe Biden, where the LLM might begin with recent facts and then delve into his early career. The initial retrieval might not capture all these details in one attempt, leading to potential hallucination when essential facts are missing.
This research addresses this issue by proposing methods to efficiently fetch additional documents during the generation process, ensuring a more comprehensive and accurate set of information for the LLM.
There are two ways to perform this retrieval task.
Insert the template into the prompt so that during generation, it can produce a signal indicating when to execute retrieval. For instance, you can say, “Joe is a teacher at SEARCH[Joe's teaching location]". Once the cue "SEARCH" is generated, the system will perform a search and collect the pertinent documents.
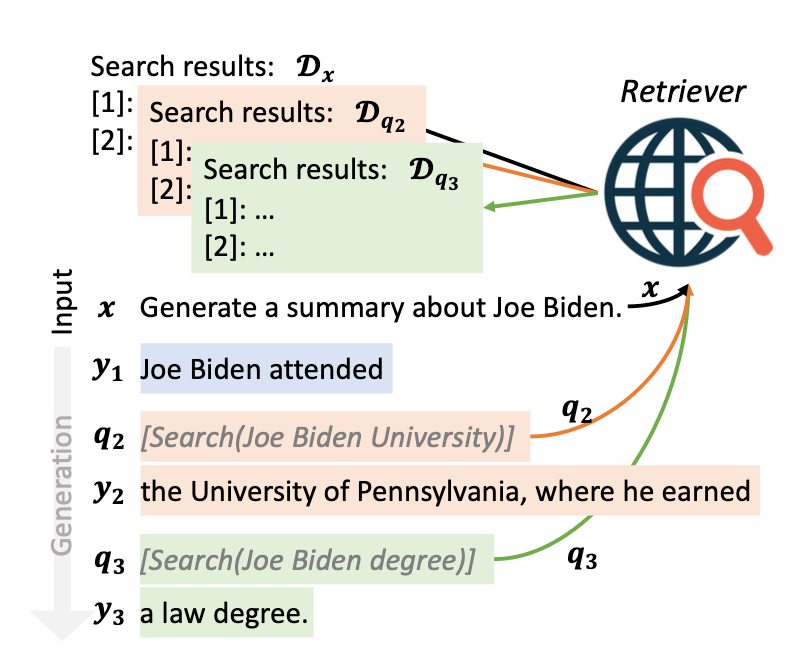
Another way is to check for low-confidence tokens in each generated sentence. This signals that the model is uncertain about this generated sentence, which might contain some weird facts. If such tokens are found, that sentence is discarded and is used to retrieve additional documents and feed them into LLM to run another generation. This process is repeated for every sentence until it reaches the end of the generation.
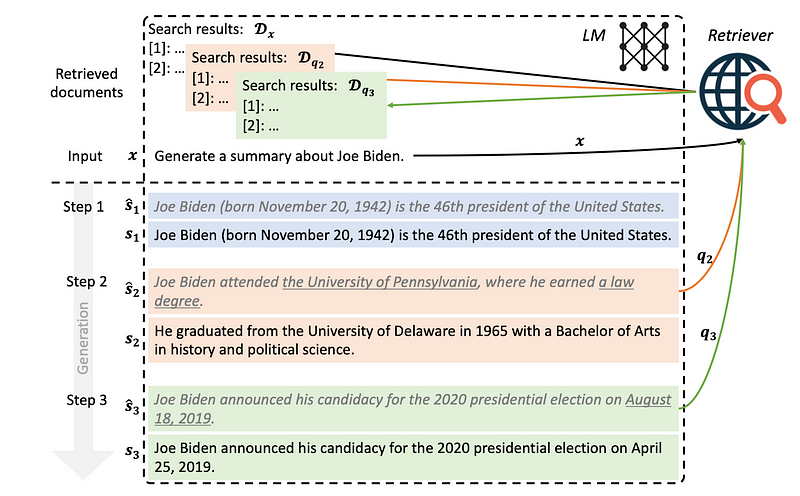
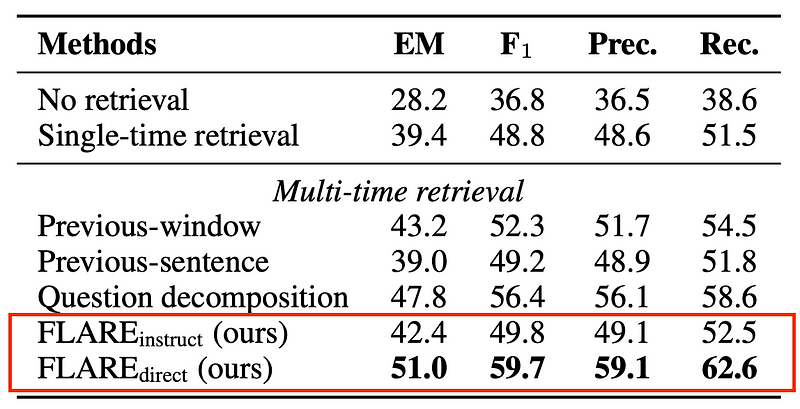
Let’s call the first method FLARE instruct and the second one FLARE direct. The instruct variant performs better than NoRetrieval or single-time retrieval. However, the direct variant outperforms the instruction by a huge margin. Thus, the remaining of the discussion in the blog will focus on the direct variant.
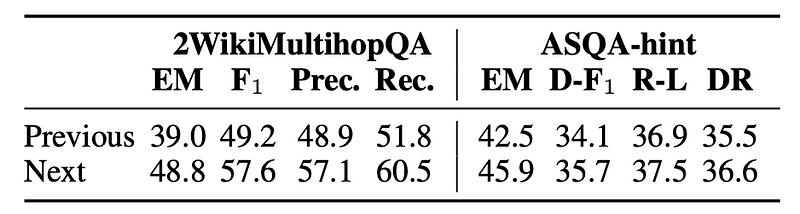
We may wonder why the newly generated sentence is used for running retrieval. If the new sentence is incorrect, shouldn’t we use the previous sentence instead? To answer this answer, the researchers ran an empirical experiment and compared the two. For simplicity, let’s refer to the newly generated sentence as the “next” sentence.
Using the next sentence (without dropping any tokens) results in a higher score than using the previous sentence. Perhaps, using the previous sentence does not align with what LLM is trying to generate next. And even though the next sentence has some low-confidence tokens, it may still contain useful information. For example, the next sentence is “The color of the grass is purple”. While “purple” is incorrect in most contexts, the retrieval system might focus more on the initial phrase like “color of the grass”, which can be helpful to the generation.
Given that using the next sentence shows better performance, in the next section, we will cover only use cases for the next sentence.
Now, let’s think about how to utilize the newly generated sentence as a search query. Are they simply input directly into the search engine? There are two methods for doing this:
Implicit masking. This will mask tokens that have a probability below a certain threshold $\beta$.
Explicit query by question generation. This involves taking the next sentence and inputting it into another model to create questions. Subsequently, these questions are utilized to retrieve relevant documents.
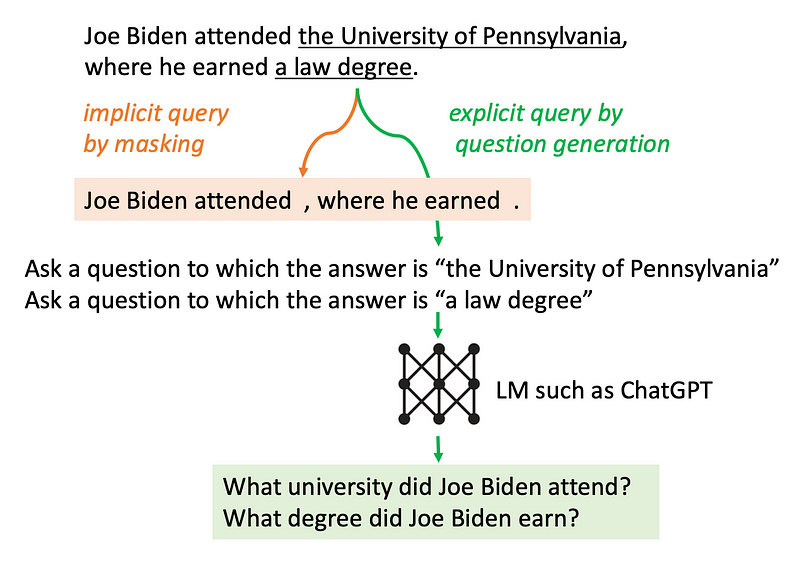
Implicit vs. Explicit. Both methods exhibit comparable performance. However, explicit generation involves additional steps, such as employing another language model for generation, leading to significantly higher computational resource consumption. As a result, the implicit approach appears to be a more practical and resource-efficient option.
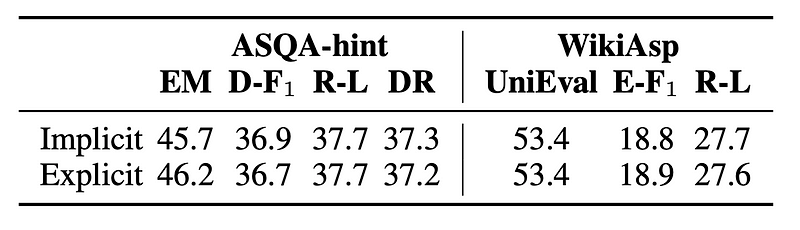
Different threshold β for Implicit.
β=0 means that all tokens are kept and won’t be dropped.
β=0.1 means tokens with a probability less than 10% will be dropped.
From the table below, dropping those low-confidence tokens generally leads to higher performance, compared to keeping everything. But note that even when we keep all the tokens, the performance drops only around 0.02 points. This is surprising since the sentence contains inaccuracies that could potentially lead to incorrect retrieval, yet the overall impact on performance is relatively small.
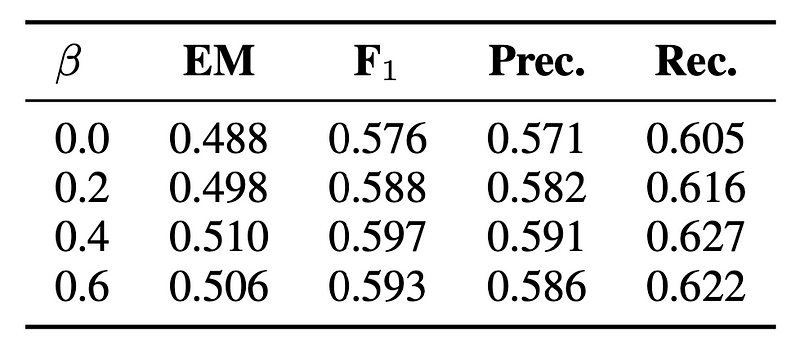
This work primarily focuses on retrieving documents to assist LLM with the generation. When generating a sentence, the system checks the confidence level of each token. If any token has a low confidence (or low probability), that sentence is discarded and is used as a query to retrieve additional documents. These retrieved documents are then employed to aid in the sentence generation process. In essence, the system evaluates the quality of a sentence before finalizing the output. If the quality is questionable, it will fetch additional documents and re-generate.
Jiang, Zhengbao, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. “Active retrieval augmented generation.” arXiv preprint arXiv:2305.06983 (2023).