Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks
Narrowing performance gap with cross-encoder using weakly labeled data
Introduction
In recent years, the advancement of natural language processing (NLP) models has revolutionized various language-related tasks, including sentence scoring and retrieval. Two prominent methods for scoring pairs of sentences are cross-encoders and bi-encoders. Cross-encoders process both sentences together by performing full attention, while bi-encoders independently convert each sentence into a dense vector and use cosine similarity to score the pair.
In the following figure, cross-encoders are generally better than bi-encoders, but they are slower when comparing two sentences. For instance, if you want to compare one sentence against 1,000 others, cross-encoders have to create and score 1,000 pairs, which is not practical for retrieval tasks. On the other hand, bi-encoders convert each sentence into a vector, making it faster to compare them directly without any extra calculations.

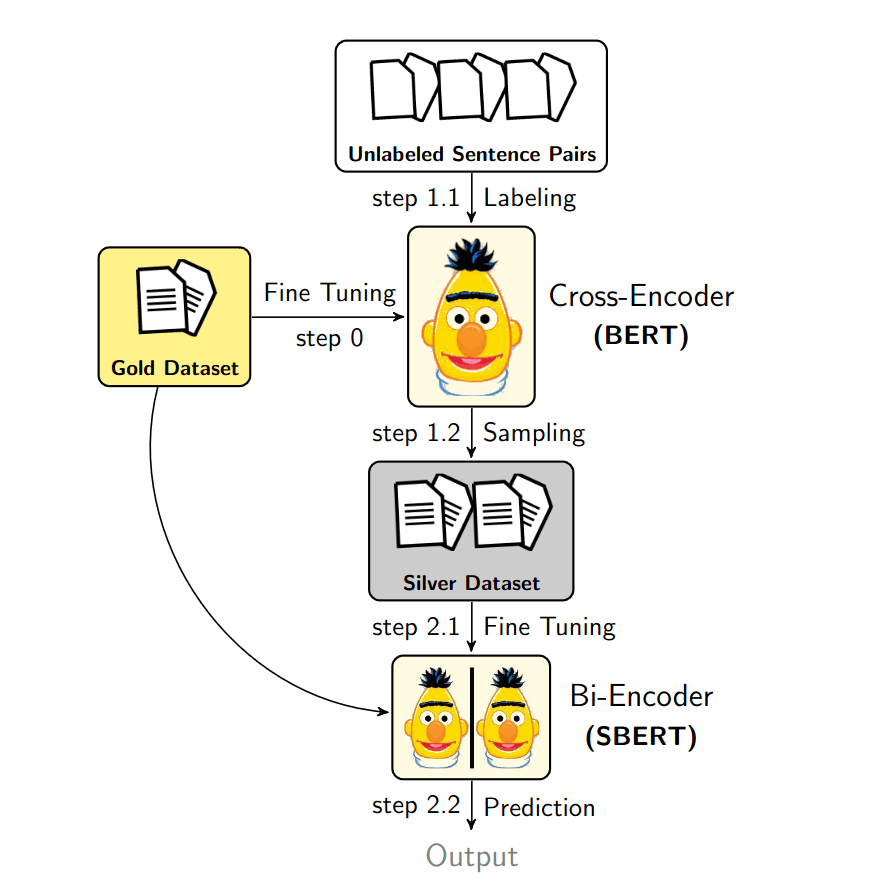
To address the limitation of bi-encoders, this paper aims to improve the model by using data augmentation so that they perform more similarly to cross-encoders.
AugSBERT
The idea is to take a trained cross-encoder model and use it to label unlabeled sentence pairs. Then, these weakly labeled pairs are used for training the bi-encoder model. The intuition is to push the bi-encoder model to perform better by learning from the cross-encoder models.

Regarding obtaining unlabeled sentence pairs, it is quite easy to get negative pairs by negative random sampling. The problem is to get positive pairs. To remedy this, Okapi BM25 is used to embed a sentence. And ElasticSearch is used to retrieve top K similar sentences, which will be evaluated by the cross-encoder model.
These weakly labeled sentence pairs are combined with the golden dataset and are used for training the Bi-Encoder model.
Result
As anticipated, the bi-encoder (SBERT) performs less well than the cross-encoder (BERT). However, by using data augmentation introduced earlier, AugSBERT-BM25 achieves better performance than SBERT, narrowing the gap with the cross-encoder. This demonstrates the effectiveness of using cross-encoders to generate weakly labeled sentence pairs for further improving bi-encoders.

Conclusion
In conclusion, this paper introduces a novel approach to improve the performance of bi-encoder models in scoring sentence pairs by leveraging cross-encoders for data augmentation. The method involves using a pre-trained cross-encoder model to label unlabeled sentence pairs, which are then combined with the golden dataset for training the bi-encoder model. By incorporating weakly labeled pairs, the bi-encoder model (AugSBERT-BM25) demonstrates significant performance gains over the traditional bi-encoder (SBERT) and narrows the performance gap with the cross-encoder (BERT). This approach effectively harnesses the strengths of cross-encoders to enhance the capabilities of bi-encoders in retrieval tasks.
Reference
Thakur, N., Reimers, N., Daxenberger, J., & Gurevych, I. (2021, June). Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 296-310).



