DeBERTa: Enhancing Token Positioning Awareness in BERT
Leveraging Positional Information for Improved Language Understanding
Introduction
Transformers, which are models based on the attention mechanism, can focus on different parts of a sentence simultaneously. However, there is a hypothesis that during this process, the model might lose some information about the positioning of words. The transformers mainly pay attention to the semantic meaning of the words, but they lack clear context about whether those words come before or after a specific word. Although absolute positioning embedding is initially provided to address this issue, it is hypothesized that this embedding may not effectively retain the positional information over time.
To address these concerns, DeBERTa was introduced as a way to enhance the transformer model's awareness of the positioning of each token. DeBERTa focuses on two key aspects: relative positioning and absolute positioning.
Relative positioning considers the distance between two words, as well as the order in which they appear. This helps the model understand the relationship between different words in terms of their position.
Absolute positioning, on the other hand, takes into account the exact position of a token within a sentence. For example, it recognizes that the subject of a sentence typically appears near the beginning. In traditional transformer models, this positional information is incorporated at the input layer. However, DeBERTa places greater emphasis on absolute positioning by incorporating it at the top of the layers, right before the softmax layers.
Intuitively, during the training process, DeBERTa is designed to grasp contextual information in the initial layers. As the information flows through these layers, the model accumulates blocks of contextual understanding. Finally, at the end of the model, the accumulated contextual information is combined with the absolute positioning to make predictions. This approach ensures that the model benefits from both the early contextual understanding and the precise positioning information when making its final decisions.
Architecture
Disentangled Attention
The Transformer model has a limitation where it combines both the position and content of each token into a single vector. This can prevent the model from effectively utilizing positional information. To address this issue, DeBERTa uses two separate vectors for each token: one for content $H$ and another for position $P$.
By introducing an additional vector, we also need to modify the attention mechanism to take advantage of the positional information.

\(A_{i,j}\) is the attention score between token $i$and $j$. Each token has content $H$ and position $P$ embedding. With the original Transformer attention, there are only \(H_iH_j^T\) which is content-to-content attention. Now three extra terms correspond to content-to-position, position-to-content, and position-to-position. However, the last one is removed because it does not contribute much to the end result.
$P$ is a shared embedding matrix that captures the distance embedding between two tokens. This does not consider any semantic meaning of the tokens, but only for their positions. For instance, we measure the relative distance \(\delta(i,j)\) between token $i$ and $j$. And this distance is represented by an embedding \(P_{i|j}\).

k is the maximum distance between two tokens. Note that this distance can not be negative. Even when a token locates before/after another, the distance will always be positive. Meaning, we just shift the range so that it captures only positive values.
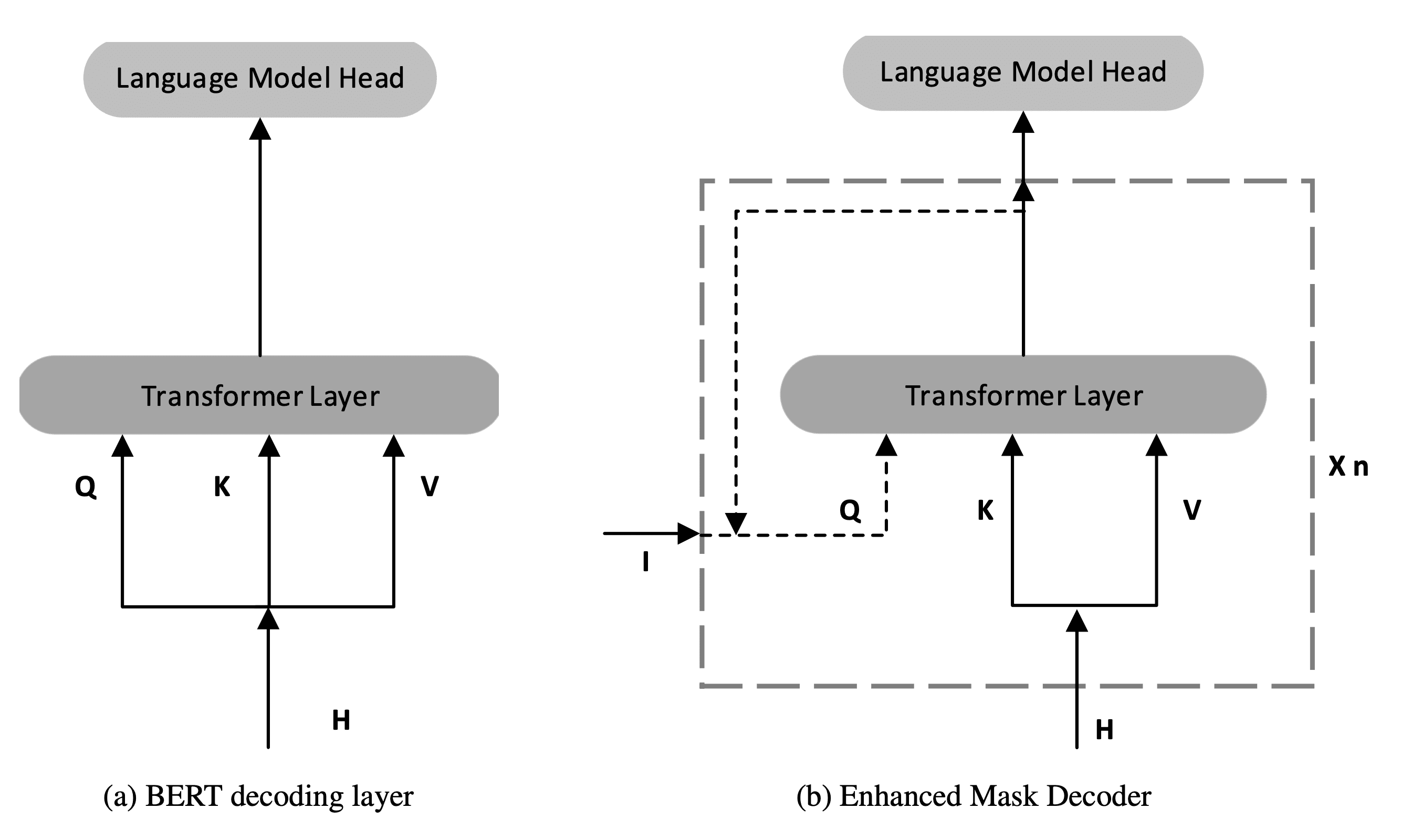
Enhanced Masked Decoder
DeBERTa also tries to improve the positioning with absolute position embedding. In the original Transformer, this embedding is incorporated at the input layers along with token embedding. DeBERTa does the other way around by placing it at the last layers, right before the softmax. The idea is for the MLM to be aware of the absolute position before predicting the masked tokens.
Specifically, DeBERTa adds $n$ extra layers. The way they incorporate the absolute position embedding is by modifying the query embedding $Q$. Typically, we get $Q$ from $H$. Instead, this takes from another vector $I$. And this $I$ can be any arbitrary information necessary for decoding. For our use case, $I$ refers to the absolute position embedding.

Result
DeBERTa outperforms BERT, RoBERTa and XLNet on all the experimented tasks as listed below. This suggests that making the model more aware of the position yields quite an interesting result.


Conclusion
In conclusion, DeBERTa offers a promising solution to address the limitations of the Transformer model in capturing and utilizing positional information. By introducing separate content and position embeddings, along with modifications to the attention mechanism, DeBERTa enhances the model's understanding of token positioning. The incorporation of relative and absolute positioning leads to improved performance across various tasks, surpassing previous models like BERT, RoBERTa, and XLNet. This showcases the significance of considering token positioning for advanced language modeling tasks.
Key Takeaway
There are two main concepts in DeBERTa, (i) separation of a token embedding into content and position embedding by using disentangled attention, and (ii) moving the absolute position embedding to the last layers to make the MLM more aware of the position when making a prediction.
DeBERTa outperforms BERT, RoBERTa and XLNet.
References
He, P., Liu, X., Gao, J., & Chen, W. DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION. In International Conference on Learning Representations.