DeBERTa-v3: Mastering Language Comprehension with Disentangled Attention and GAN-inspired Training
The Powerful Fusion of DeBERTa and ELECTRA
Overview
DeBERTa-v3 is a Transformer-based model that combines the techniques from DeBERTa v1 and ELECTRA. DeBERTa enhances the model's understanding of token positioning through attention disentanglement. On the other hand, ELECTRA deviates from the traditional approach of using a Transformer encoder like BERT for masked language modeling (MLM) training. Instead, ELECTRA adopts a generator and discriminator approach inspired by generative adversarial networks (GANs).
In ELECTRA, certain input tokens are masked, and the generator component attempts to predict and fill in these masked tokens. The resulting sentence is then fed into the discriminator, whose task is to determine whether each token has been replaced. Notably, in this GAN-style training, there is no direct gradient back-propagation from the discriminator to the generator. These two components, the generator and discriminator, operate as separate networks. However, they can learn from each other by sharing the embedding layers, which we will discuss in more detail below.
It's important to note that for further fine-tuning on downstream tasks, the encoder module is removed, and the discriminator is retained. This allows the model to leverage the knowledge gained during the GAN-style training process.
Gradient-Disentangled Embedding Sharing

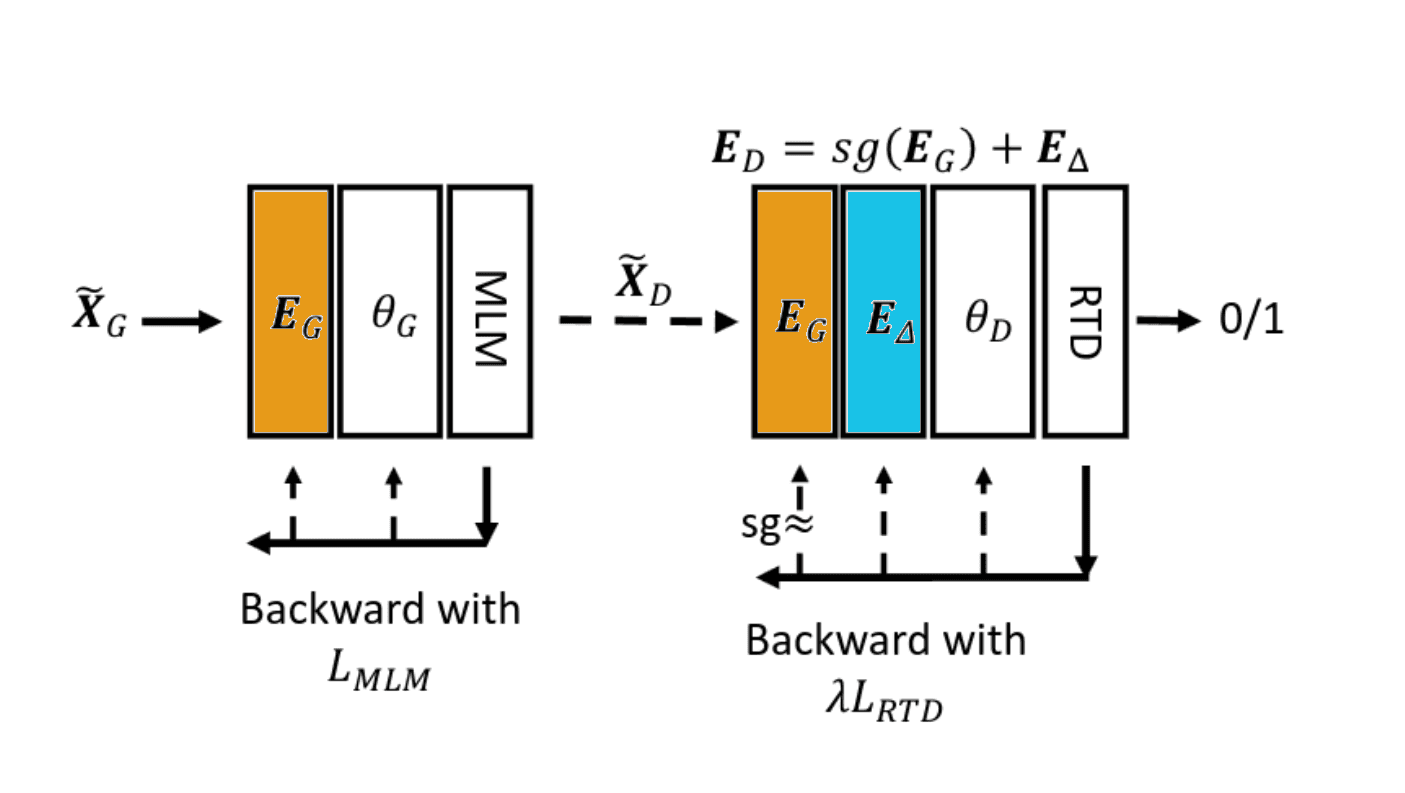
Figure 1. Different design styles between different embedding sharing methods.
(Figure 1a) In the original ELECTRA model, the generator and discriminator share the same embedding, denoted as $E$. This approach allows the embedding to learn from both the masked language modeling (MLM) and replaced token detection (RTD) objectives. However, it introduces a "tug-of-war" problem, where the RTD objective pushes the embedding in one direction while the MLM objective pulls it in another.
(Figure 1b) To investigate this issue and confirm that MLM and RTD have different effects on weight updates, an experiment was conducted. In this experiment, the embeddings are no longer shared between the generator and discriminator. Instead, they each have their own embeddings, denoted as \(E_G\) and \(E_D\) respectively. Importantly, there is no signal passed from the discriminator to the generator. To evaluate the embeddings, a cosine similarity measurement is performed between two tokens. Figure 2 (NES) illustrates the results, showing that the generator's embeddings are more similar to each other, in contrast to the discriminator's embeddings.

Figure 2. ES: Embedding sharing. NES: No embedding sharing. GDES: Gradient-disentangled embedding sharing.
(Figure 1c) The main proposal of this paper is to introduce a re-parameterization of the discriminator's embedding. The aim is to ensure that the generator's embedding \(E_G\) is solely influenced by the masked language modeling (MLM) objective, thereby avoiding the "tug-of-war" dynamics. On the other hand, the discriminator's embedding \(E_D\) is represented as \(E_D = \text{sg}(E_G) + E_\triangle\) where \(\text{sg}\) denotes the stop gradient operation, preventing the gradient from propagating to \(E_G\). Essentially, the replaced token detection (RTD) objective exclusively affects \(E_\triangle\), while \(E_D\) can still incorporate information from \(E_G\).
Result
DeBERTa-v3 essentially outperforms RoBERTa, XLNet, ELECTRA, and DeBERTa-v1 on downstream tasks.
DeBERTa-v3-small even performs better than BERT and is on par with RoBERTa.
DeBERTa-v3-xsmall is slightly better than DeBERTa-v3-small.

Key Takeaway
DeBERTa-v3 leverages the following key components:
Attention disentanglement from DeBERTa, enhancing the model's understanding of token positioning.
GAN-style training inspired by ELECTRA, where the discriminator is employed for downstream tasks while discarding the generator.
A re-parameterization of the discriminator embedding to mitigate the "tug-of-war" dynamics, enabling the gradients from both MLM and RTD objectives to be utilized effectively.
These elements form the foundation of DeBERTa-v3, combining attention disentanglement, GAN-style training, and a refined discriminator embedding to improve the model's performance and flexibility in various natural language processing tasks.
References
He, P., Gao, J., & Chen, W. (2021). DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing. ArXiv, abs/2111.09543.
https://www.kaggle.com/code/debarshichanda/pytorch-feedback-deberta-v3-baseline/notebook