LLaMA: Open and Efficient Foundation Language Models
Large Language Model for Commercial Purpose

Search for a command to run...
Large Language Model for Commercial Purpose
No comments yet. Be the first to comment.
Summary of Active retrieval augmented generation paper

Classifying digits using Apple M1 GPU

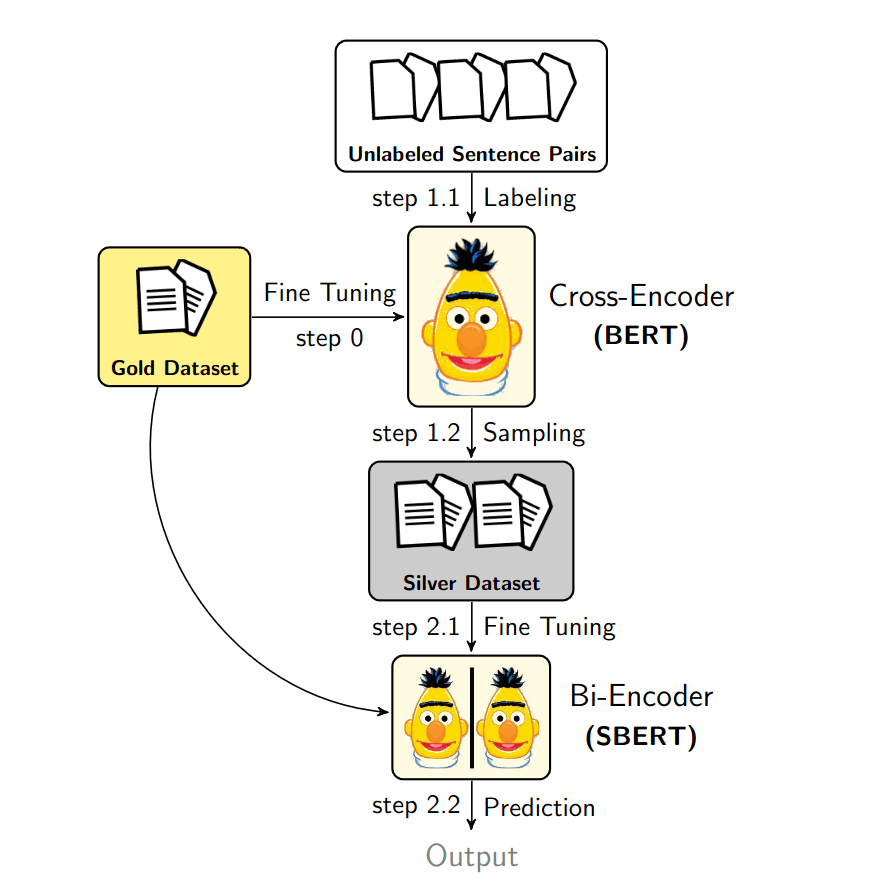
Narrowing performance gap with cross-encoder using weakly labeled data
Training data-efficient image transforms & distillation through attention

The introduction of LLaMA, a large language model, aims to address the limited availability of open-sourced language models. Unlike many existing models, LLaMA is trained on open-source data, making it accessible for commercial use by any company. Surpassing GPT-3 on various benchmark tasks, LLaMA showcases superior performance. Moreover, it stands on par with Google's PaLM model, despite being significantly smaller in size, making it an efficient and powerful option for natural language processing tasks.
Just like other LLM models, this uses the Transformer model but with a small modification.
Use RMSNorm to normalize the input of each transformer sub-layer instead of at the output
Use the SwiGLU activation function instead of ReLU
Use Rotary Positional Embedding (RoPE) instead of positional embedding
Use only open-source data in the English language. This includes CommonCrawl, C4, Github, Wikipedia, Books, ArXiv and StackExchange.
Use 1T tokens to train. One work recommends training the 10B model on 200B tokens, but LLaMA can bring the performance further on the 7B model with 1T tokens.
Use Byte-Pair encoding (BPE) for tokenization. Split all numbers into individual digits and fall back to bytes for unknown UTF-8 characters.
Several techniques are used to speed up the training time.
Use causal multi-head attention to reduce memory usage and runtime. Basically, LLaMA does not store attention weights and doesn’t compute the key/query score that is masked.
Pre-calculate some expensive activation layers like the Linear layer. They re-implement the backward function instead of relying on PyTorch autograd.



In conclusion, the LLaMa language models have demonstrated remarkable performance in the realm of natural language processing. LLaMa-13B has proven to outperform the larger GPT-3 (175B) on various benchmark tasks, showcasing its efficiency and effectiveness. Furthermore, LLaMa-65B has shown comparable performance to the powerful Google PaLM-540B and Chinchilla-70B models. This highlights the significant advancements made in developing more accessible and efficient language models, making LLaMa a promising option for companies seeking powerful language processing capabilities.
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., ... & Lample, G. (2023). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.