Navigating the Limitations of Large Language Models in NLP
5 Things to Know Before Applying LLM models

Search for a command to run...
5 Things to Know Before Applying LLM models
No comments yet. Be the first to comment.
Summary of Active retrieval augmented generation paper

Classifying digits using Apple M1 GPU

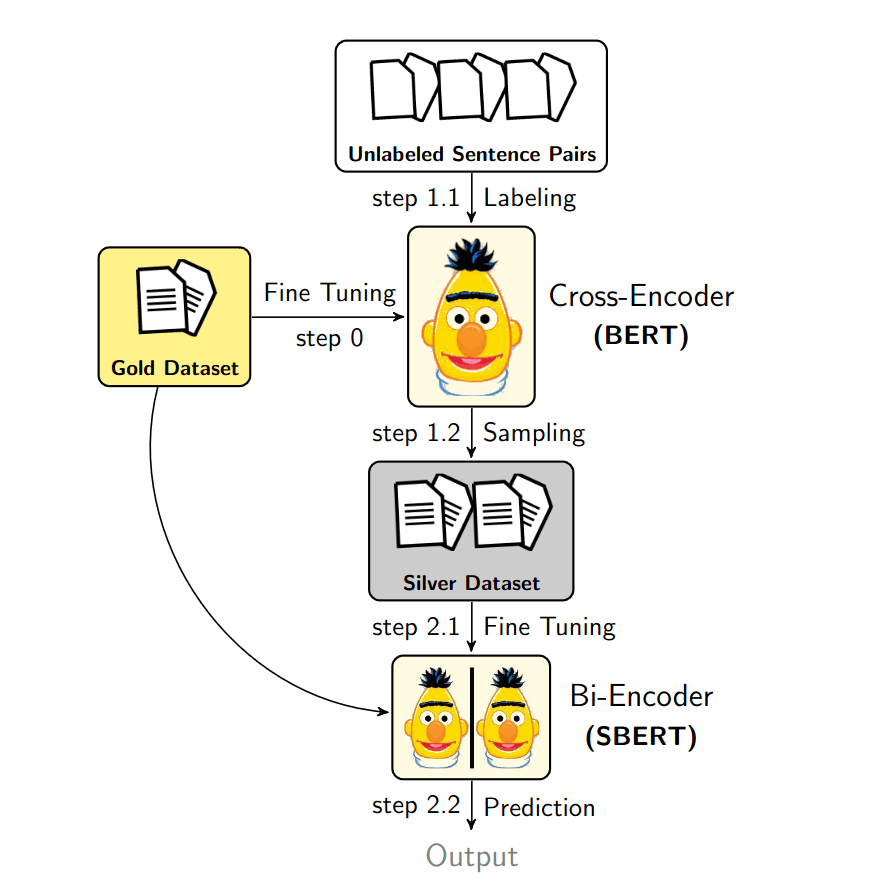
Narrowing performance gap with cross-encoder using weakly labeled data
Large Language Model for Commercial Purpose

Training data-efficient image transforms & distillation through attention

Large language models, such as GPT-3, have made significant strides in natural language processing tasks such as translation, summarization, and question-answering. These models are trained on vast amounts of data and are able to generate human-like text with impressive fluency. However, it is important to recognize that these models have several limitations that should be considered when applying them to real-world tasks.
One limitation of large language models is their reliance on data. While access to large amounts of data has allowed these models to achieve impressive results, it also means that they may not generalize well to languages or domains where data is scarce. This can be a problem for low-resource languages, or for tasks that require specialized knowledge in a particular domain. For example, a large language model trained on English text may struggle to translate or summarize text in a low-resource language that it has not been specifically trained on. Similarly, a model trained on general web text may not have the specialized knowledge required to accurately summarize or answer questions about a particular domain, such as biology or finance.
Another limitation of large language models is their inability to fully understand the context and meaning of the words they process. These models are based on patterns in the data and are not able to reason or infer in the same way that humans can. This can lead to mistakes or inappropriate responses when the model is faced with novel or unexpected situations. For example, a model may generate text that is coherent and fluent but is not actually appropriate or relevant to the given prompt or context.
In addition to these limitations, large language models can be computationally expensive to train and run, which can make them impractical for certain applications. The computational requirements for training these models can be significant, and running the models in production can also require a large amount of computational power. This can make it challenging to use these models in real-time applications or on resource-constrained devices.
The energy requirements for training and running large language models are also a concern. The process of training these models can be energy-intensive, and there have been calls for more sustainable approaches to training and deploying these models.
Finally, large language models have raised ethical concerns, particularly around the potential for bias in the data they are trained on. If the data used to train a model is biased, the model may perpetuate and amplify those biases in its output. This has led to calls for more diverse and representative data to be used in the training of these models, in order to ensure that the output is fair and unbiased.
Overall, while large language models have achieved impressive results in natural language processing tasks, it is important to recognize their limitations and consider how they may impact the applications they are used for. These models can be a powerful tool for generating human-like text, but it is important to carefully evaluate their limitations and ensure that they are used in an appropriate and responsible manner.