The Unintended Side Effects of Large Language Models
Understanding and Mitigating Negative Consequences of LLM

Search for a command to run...
Understanding and Mitigating Negative Consequences of LLM
No comments yet. Be the first to comment.
Summary of Active retrieval augmented generation paper

Classifying digits using Apple M1 GPU

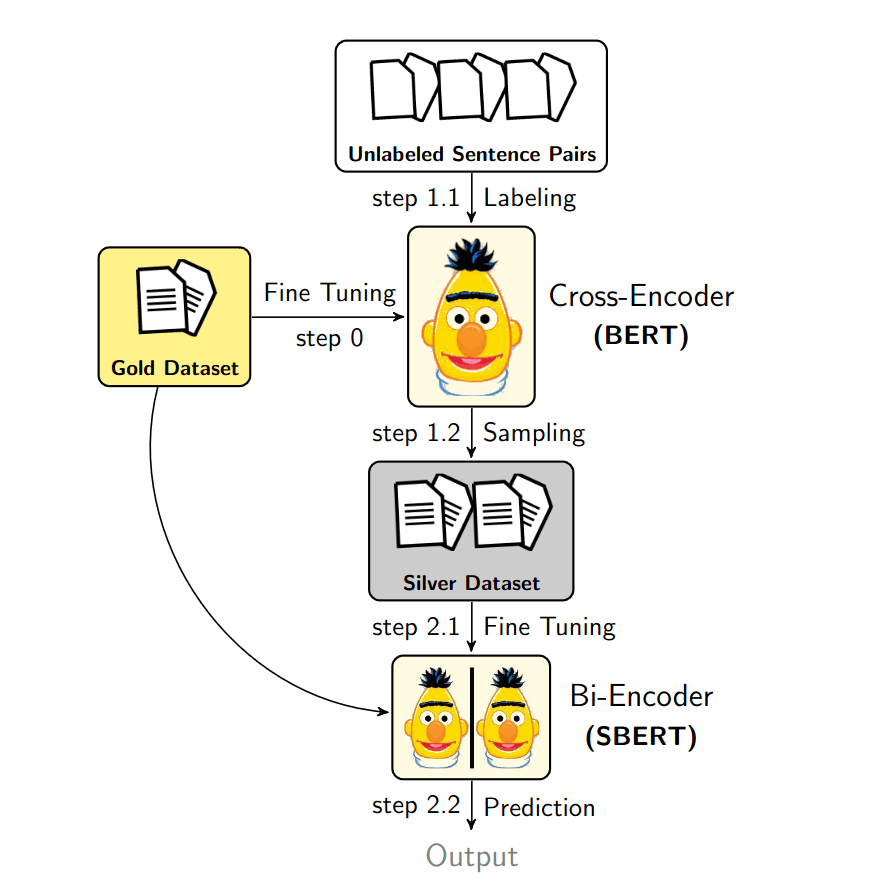
Narrowing performance gap with cross-encoder using weakly labeled data
Large Language Model for Commercial Purpose

Training data-efficient image transforms & distillation through attention

Large language models, such as OpenAI's GPT3/4 and Google's BARD, have made significant strides in natural language processing and have found a wide range of applications in fields such as language translation, content generation, and question & answering. These models are trained on massive amounts of data and are able to generate human-like language with remarkable accuracy. However, as with any technological advancement, there are also unintended consequences associated with the use of large language models. In this blog post, we will explore some of their side effects. By understanding these side effects, we can work to mitigate their impact and ensure that the benefits of large language models are realized while minimizing their negative consequences.
Perpetuation and amplification of biases in language and society. Large language models can perpetuate and amplify biases and prejudices in their outputs if they are trained on biased or unrepresentative data. For example, if a language model is trained on data that include gender or racial stereotypes, it may learn to generate biased or discriminatory language patterns. This can have serious consequences for individuals and society as a whole, perpetuating discrimination and reinforcing existing power structures and societal inequalities.
Amplification of misinformation or fake news if trained on biased or unverified data. Large language models can be used to generate convincing and plausible fake news or misinformation if they are trained on biased or unverified data. For example, a language model trained on data that includes conspiracy theories or other false information may generate outputs that reinforce these narratives, making it more difficult to combat misinformation.
Limited ability to understand the context and common sense reasoning. While large language models are very good at predicting language patterns, they often struggle with understanding context and common sense reasoning. For example, a language model may struggle to understand the difference between the literal and figurative meanings of a word or phrase, leading to errors or misunderstandings in its outputs.
Difficulty in auditing for biases and ethical concerns. Large language models can be very complex and difficult to understand, making it challenging to audit them for biases or ethical concerns. For example, it may be difficult to determine whether a language model is generating biased outputs if the biases are subtle or implicit.
Potential for generating offensive or inappropriate content if trained on biased or inappropriate data. Large language models can generate offensive or inappropriate content if they are trained on biased or inappropriate data. For example, a language model trained on data that includes hate speech or other offensive languages may generate outputs that are offensive or inappropriate.
To mitigate the unintended side effects of using large language models, there are several potential solutions that can be adopted. One of the key ways to address these issues is to diversify the training data used to develop the models. By using data that represents a diverse range of viewpoints and experiences, we can help prevent the perpetuation of biases and promote a more inclusive perspective in the model's outputs.
Another solution is to verify and fact-check data before using it to train the model. This approach can help prevent the amplification of misinformation or fake news, which can be especially important in sensitive areas such as finance or healthcare. Additionally, improving the model's ability to understand the context and common sense reasoning is another approach that could help to address its limitations. This can be achieved through the development of new algorithms and models that incorporate this type of knowledge.
Regular bias and ethical audits can also help ensure that the model is not perpetuating biases or generating offensive content. Such audits can identify any ethical concerns or biases in the model's outputs and help researchers and developers to address them proactively. Furthermore, enhancing the transparency and interpretability of the model could help researchers better understand how it arrives at its outputs and detect biases more easily. This can be achieved through the development of tools and methods to interpret and visualize the model's outputs.
Finally, establishing ethical guidelines could help promote the responsible use of large language models. These guidelines could cover issues such as data privacy, bias, and accountability, and could help ensure that the models are developed and used in a responsible manner.
Through a combination of these solutions and ongoing evaluation, researchers and developers can work towards realizing the potential of large language models while minimizing their negative consequences. By addressing these issues proactively, we can ensure that these models are used to benefit society while avoiding unintended negative consequences.
In conclusion, large language models have demonstrated incredible potential in revolutionizing natural language processing and driving technological advancements in various fields. However, their use also comes with unintended side effects, such as the perpetuation of biases, the amplification of misinformation, and the potential for generating offensive or inappropriate content. It is important that we recognize and address these side effects through ongoing research, transparency, and ethical considerations. By doing so, we can ensure that large language models are developed and used responsibly while realizing their potential to enhance human communication and understanding. As with any new technology, we must remain vigilant and take proactive steps to mitigate any potential negative consequences.