Wav2Vec 2.0 Model for Cross-Lingual Phoneme Recognition
A Model for recognizing phoneme of different languages

Search for a command to run...
A Model for recognizing phoneme of different languages
could you please share the github repo or the code itself that was used to train this model? thank you!
Summary of Active retrieval augmented generation paper

Classifying digits using Apple M1 GPU

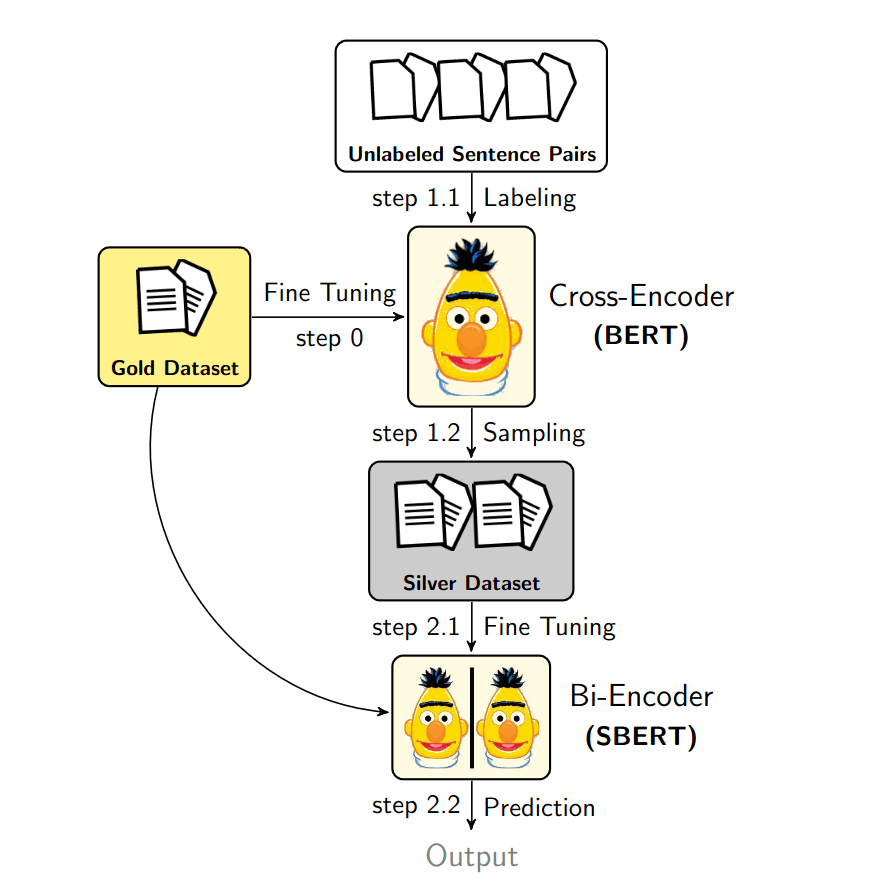
Narrowing performance gap with cross-encoder using weakly labeled data
Large Language Model for Commercial Purpose

Training data-efficient image transforms & distillation through attention

The ability to recognize phonemes, the smallest units of sound in a language that distinguish one word from another, is essential for many natural language processing tasks. In a recent paper, researchers explored the effectiveness of Wav2Vec2, a transformer-based model pre-trained on raw audio data, in recognizing phonemes automatically generated from audio. They added a Connectionist Temporal Classification layer to the pre-trained model for phoneme recognition and evaluated its performance on the BABEL and CommonVoice datasets. The study found that Wav2Vec2 achieved high phoneme recognition performance on both seen and unseen languages and recommended the use of a multilingual pre-trained model for downstream tasks in multiple languages.
A Transformer-based model, called Wav2Vec2 outperforms many of the existing work, particularly in low-resource language. This work explores how well this model behaves for the task of translating from audio to phonemes. Note that a phoneme (/ˈfoʊniːm/) is a unit of sound that can distinguish one word from another in a particular language (Wikipedia). It represents a proper way to pronounce a word.
Briefly, how Wav2Vec2 works is that it pretrains using only raw audio via self-supervision. No preprocessing or label data is needed.
It maps every 25ms of audio strided by 20ms into a latent speech representation \(z_t\)
For each time step, \(z_t\) goes into the Transformer model and produces the contextual representation \(c_t\) (like a regular Transformer, which also utilizes $z$ at other time steps).
\(z_t\) is also discretized into \(q_t\). In other words, It gets converted into a label integer.
The model learns to determine which \(q_i\) corresponds with \(c_t\).
After pretraining the Wav2Vec2, a Connectionist Temporal Classification (CTC) layer is added on top of the transformer model so that it can predict the phoneme for each timestep. Note that for this step, the model no longer learns to find the corresponding \(q_i\) and \(c_t\). It focuses only on getting the right phoneme prediction.
The dataset used for this work is BABEL and CommonVoice. These datasets, however, do not contain any label data for phonemes. Instead, separate tools are used to automatically generate those labels, i.e., ESpeak or Phonetisaurus. Note that only one tool should be used for consistent labeling.

For each column language, (for example de), each model is trained on all languages besides de and is tested on that language. The performance of this zero-shot is quite astounding.

Zero-Shot performance of different pre-trained models.
XLSR-53 is a multilingual pretrained model (the one we have been discussing so far). w2v LV-60K is the same model architecture but it's pretrained on English + language specified by each row. No pretrained refers to the original model that pretrained only using the English language. The score is phoneme error rate (PER), the lower the better.
Having no pretrained achieves the worst performance. We simply can't rely only on English speech and accent. It's not enough. At least, pretrained on the target language. It shows substantial improvements over the non-pretrained one. As for XLSR-53, it even shows improvements further. Hence, why not just pretrained once on all languages, and just use that. Then, it makes downstream tasks a lot easier.
Wav2Vec2 is trained on CommonVoice and BABEL dataset using ESpeak / Phonetisaurus to create phoneme labels automatically.
It can deliver substantially high performance on phoneme recognition tasks for both seen and unseen languages.
Use a multilingual pretrained model if possible, particularly if the downstream tasks are on multiple unseen languages.